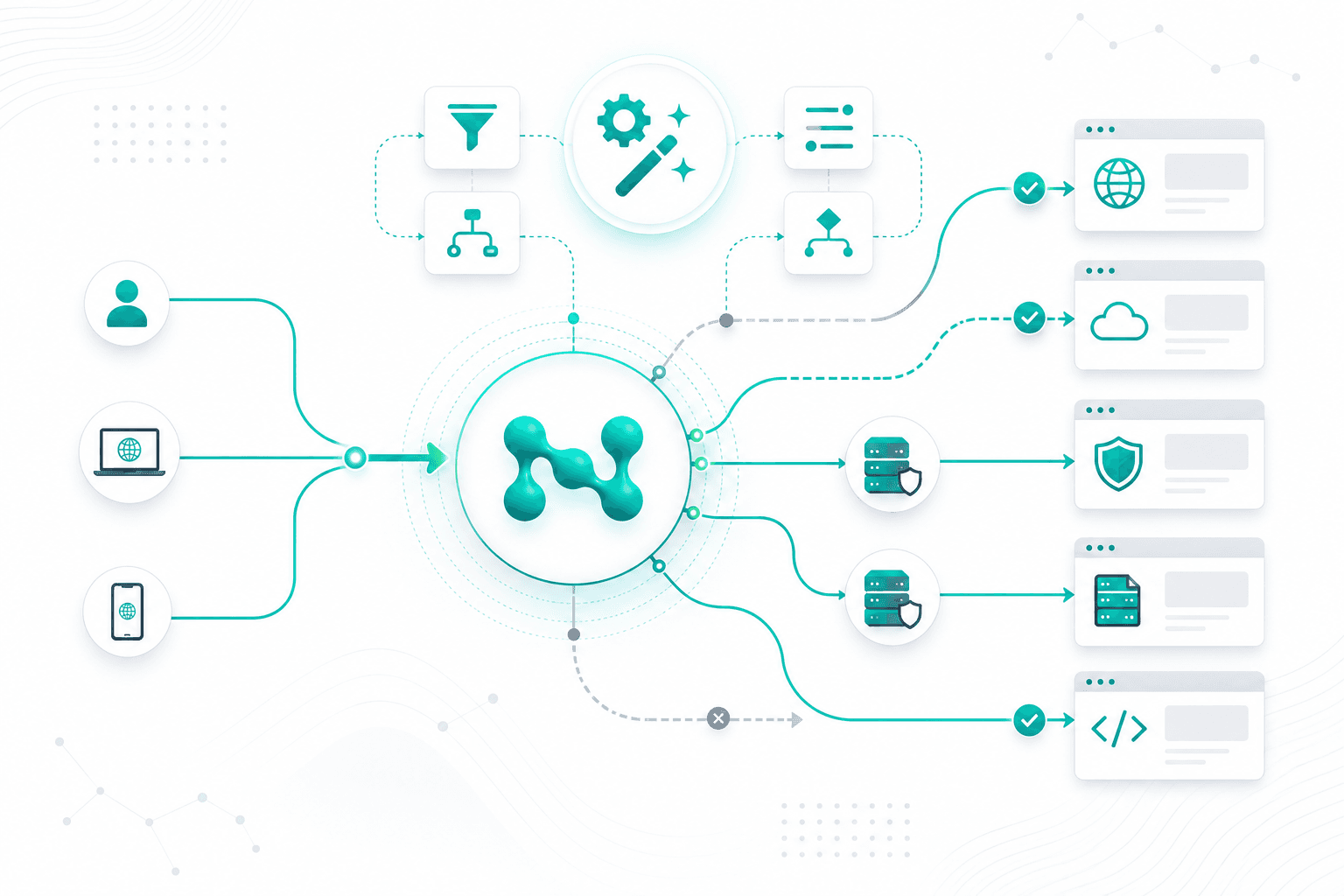
How Websites Distinguish Humans from Automation: Signals, Verification Layers, and the Logic of Anti-Bot Protection
 ·June 28, 2026·6 min read
·June 28, 2026·6 min read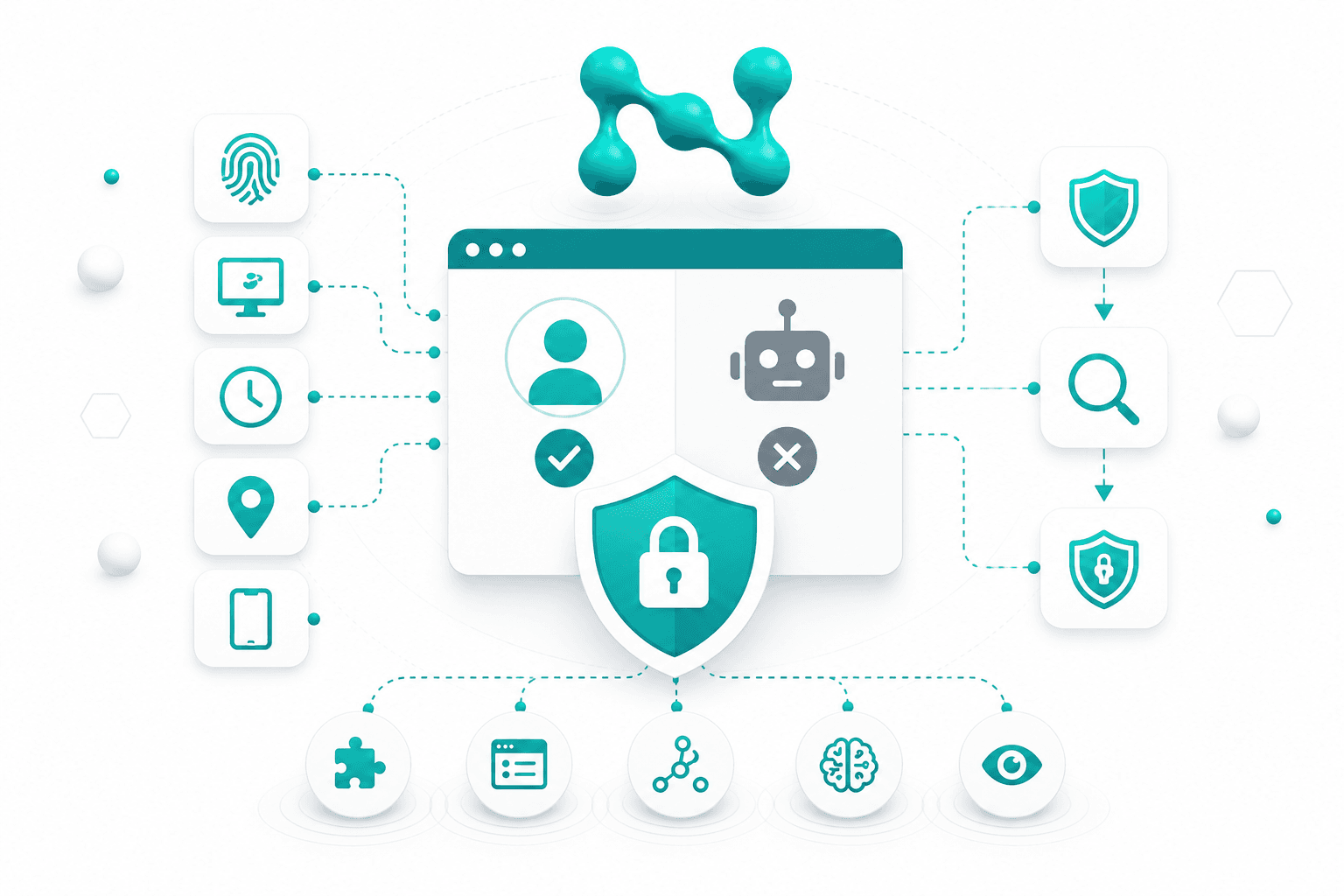
Why a Single Check Is Not Enough
Automated traffic has long ceased to be primitive. Today, websites face not only simple scripts, but also full-fledged browser environments capable of executing JavaScript, rendering pages, and imitating user actions. Against this background, standalone protection methods quickly reach the limits of their effectiveness.
Request rate checking helps filter out crude overload, but it does not provide a reliable answer as to who is actually on the other end of the connection. Device analysis makes it possible to detect an unnatural execution environment, but by itself it does not explain how the user behaves on the page. Behavioral signals are effective at identifying automation, but without technical context they, too, can be ambiguous. That is why anti-bot protection is built as a sequence of layers, where each subsequent layer refines the risk assessment.
In practice, a website does not try to issue a final verdict instantly based on a single attribute. It collects a set of signals, compares them with one another, and gradually raises the verification level only in cases where the activity appears non-standard.
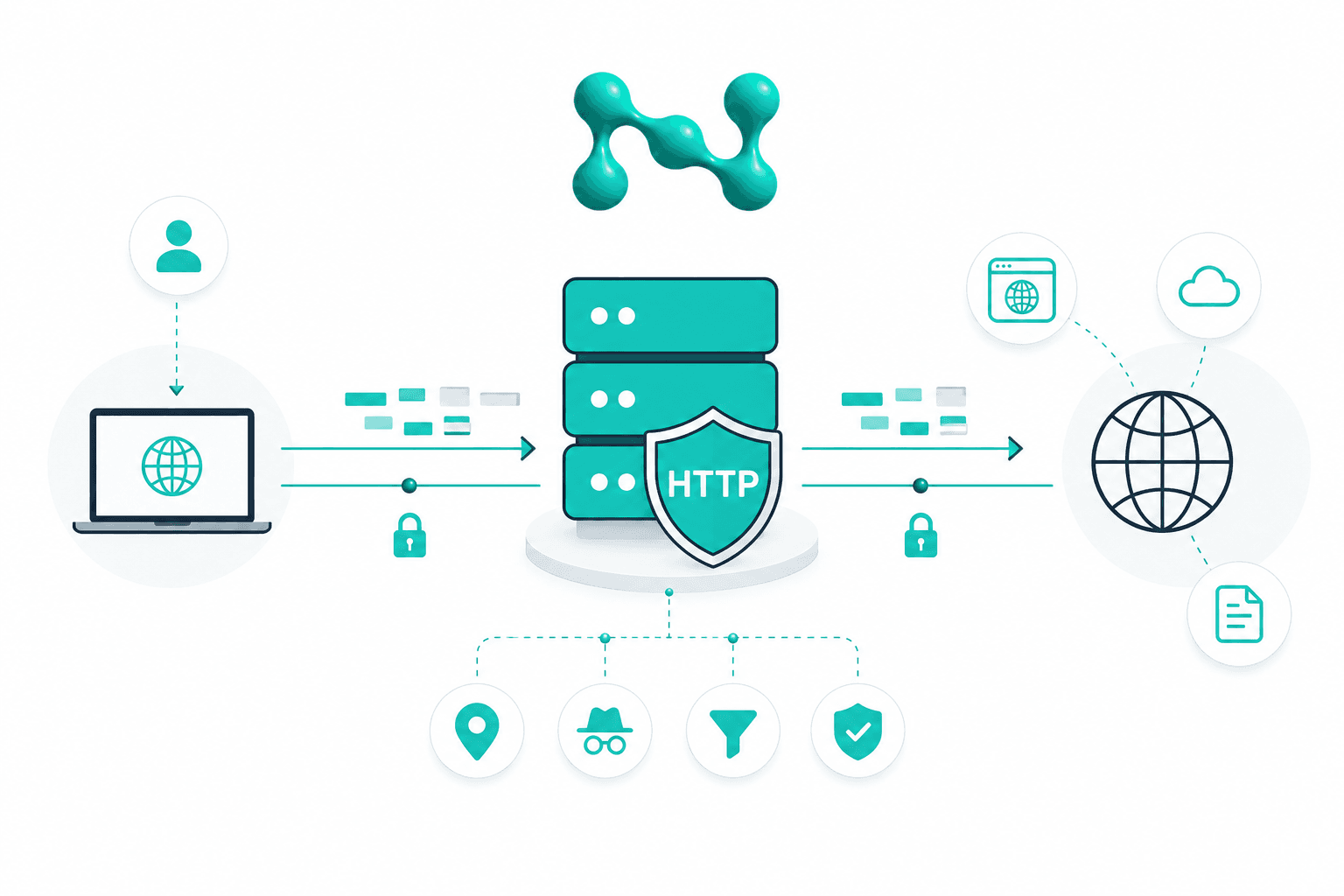
The First Layer: Network Signals and Request Frequency
The first line of assessment begins even before behavior within the page is analyzed. The server sees the source of the request, the request frequency, the sequence of calls, and the overall traffic structure. Even at this stage, a significant share of unwanted automation can be identified.
One of the basic mechanisms is IP address reputation analysis. If an address is associated with known automated traffic infrastructure, this does not mean automatic blocking, but it becomes a strong risk factor. Such addresses are usually not considered in isolation: the system also takes into account the history of activity, the nature of the requests, and the sensitivity of the target entry point.
Controlling request intensity is no less important. For this purpose, different rate-limiting models are used: fixed intervals, sliding windows, token bucket, and other schemes that make it possible to distinguish normal load spikes from an unnaturally dense flow of requests. When activity exceeds the acceptable threshold, the server may temporarily restrict access, return a 429 response code, or switch the session into enhanced verification mode.
However, the network layer alone does not fully solve the problem. It is good at detecting crude anomalies, but it is poorly suited to cases where automation distributes the load carefully and tries to appear like an ordinary user. That is why browser environment analysis comes into play next.
The Second Layer: Browser and Device Fingerprinting
Even without cookies, a website can collect enough technical signals to build a stable profile of the client environment. Such a profile is not a single parameter. It is a combination of many details, from screen size to the peculiarities of graphics and audio rendering. Individually, these attributes are rarely unique, but together they form a characteristic signature of the device and browser.
The main value of this approach lies in the fact that the fingerprint is recalculated on every visit. It is not stored as a conventional identifier on the client side, but assembled on the fly based on the current properties of the environment. Therefore, clearing the browser’s local data does not eliminate the source of the signal itself: on the next visit, the website receives roughly the same set of characteristics again.
Canvas Fingerprinting
The Canvas API allows the browser to draw graphics using JavaScript. Anti-bot systems use this not to display the interface, but to measure rendering characteristics. A script creates a hidden canvas, draws text, geometric shapes, shadows, and gradients onto it, and then reads the resulting pixel array.
Visually, the result may look the same on different devices, but at the level of individual pixels, small discrepancies emerge. These are influenced by the graphics subsystem, drivers, anti-aliasing mechanisms, font processing, and the browser engine. These differences are converted into a compact signature that helps distinguish one environment from another.
For anti-bot protection, not only uniqueness as such matters here, but also consistency. If the browser claims one type of environment, while the canvas result looks atypical for that combination of parameters, this becomes a sign of substitution or emulation.
WebGL Fingerprinting
If canvas captures the characteristics of two-dimensional rendering, WebGL provides a deeper cross-section of the graphics environment. Through WebGL, it is possible to obtain information about the graphics stack: vendor and renderer strings, available extensions, shader parameters, texturing capabilities, and other characteristics of the graphics pipeline.
In addition to reading parameters, the system can render a hidden scene and analyze the pixel output. This makes it possible to detect not only general information about the graphics subsystem, but also more subtle distinctions related to driver implementation and the browser engine.
For anti-bot analytics, internal inconsistencies are especially useful. For example, if the set of graphics capabilities fits poorly with the other declared device parameters, the website receives a signal that it is dealing with an unnatural or unstable execution environment.
AudioContext Fingerprinting
Another source of technical differences is the Web Audio API. A website can create a hidden audio context, generate a test signal, pass it through a processing chain, and then analyze the resulting numerical values. No audible sound is needed for the user: all processing takes place inside the browser.
The reason for the differences is the same as in graphical methods: the implementation of the audio stack depends on the browser, system libraries, drivers, and hardware configuration. Even if the resulting difference is imperceptible to a human, for an algorithm it can become a stable technical feature.
AudioContext is especially useful in combination with canvas and WebGL. When several independent subsystems — graphics, audio, and the overall browser environment — produce a consistent profile, confidence in the result increases. If one of the subsystems sharply deviates from the overall picture, suspicion is reinforced.
Additional Environmental Signals
In addition to advanced rendering methods, a website also takes into account simpler parameters: screen resolution, pixel density, number of logical cores, amount of available memory, color depth, system locale, time zone, font set, plugins, and other properties of the browser environment.
Taken separately, an individual parameter rarely proves anything. But when the system compares dozens of attributes at once, it begins to see not just a device, but an internally consistent — or, conversely, contradictory — client model. This is what makes fingerprinting useful in anti-bot protection: it helps detect not abstract “unusualness,” but technical inconsistencies in the browser profile.
The Third Layer: Behavioral Analysis
The technical profile of the environment answers the question of how plausible the device appears. Behavioral analysis answers another question: does the user behave like a human. It is at this level that websites track the dynamics of interaction, not just the static characteristics of the client.
Cursor Movement and Micro-Changes in Trajectory
Human mouse movements are irregular by nature. The trajectory usually contains arcs, small corrections, pauses, phases of acceleration and deceleration. Automation often leaves a cleaner and more schematic pattern: straight movements, identical speed, overly precise targeting of interface elements, and an absence of micro-fluctuations.
Modern systems do not reduce the analysis to a primitive rule such as “a straight line means a bot.” They assess the statistical profile of movements: the frequency of corrections, the distribution of pauses, the nature of acceleration, and the relationship between cursor position and interface elements.
Typing Rhythm and Form Interaction
Human text entry is usually uneven. It includes hesitations, bursts of speed, corrections, returns to previous fields, and accidental mistakes. Automated input, by contrast, often looks too uniform or too fast, especially when several fields are completed almost instantly and according to a predictable pattern.
What is analyzed is not only typing speed, but also the overall scenario of working with the form: in what order fields are filled out, how long the user thinks before submitting, whether they change the data, whether they leave optional fields empty, and whether they return to already completed parts of the form.
Site Navigation and Interaction Time
A human rarely moves through a website along a perfectly repeatable path. Their behavior depends on interest, goal, interface complexity, and page content. That is why natural sessions usually differ in browsing depth, pause duration, scrolling speed, and the sequence of transitions.
Automation, even when well configured, more often leaves a pattern: fast uniform transitions, almost identical time spent on pages, instant actions immediately after the interface loads, and the absence of meaningful pauses before important steps. If such signs recur at the level of individual sessions or groups of visits, the risk score rises.
Session Consistency
For a website, it matters not only how the user interacts at a specific moment, but also how stable the entire session appears. If, within a short period of time, client properties, network indicators, rendering characteristics, or the behavioral model change sharply, this looks suspicious.
A consistent session usually maintains a unified environmental profile and an understandable navigation logic. Inconsistency, by contrast, may indicate automated context switching, an unstable execution environment, or an attempt to conceal the source of the activity.
The Fourth Layer: Verification Mechanisms
When the combination of signals points to elevated risk, the website moves from passive assessment to active verification. This is the final stage, at which the client must confirm that the system is dealing with a real user and a full-fledged browser environment.
CAPTCHA is only one possible mechanism of this kind, and no longer the most universal one. Modern systems try to use verification sparingly, because any additional action worsens the user experience. That is why the task of anti-bot protection is not to show a challenge to everyone indiscriminately, but to display it only where the previous layers have actually detected an anomaly.
In addition to classic CAPTCHAs, lightweight interactive tasks, tests for proper JavaScript execution, timing-based scenarios, and other methods are used to ensure that the client is not merely a source of HTTP requests, but a полноценная environment with the expected browser behavior.
Sometimes the verification mechanism remains completely invisible to the user. A website may run a hidden script, wait for the correct execution of browser operations, and use the result as an additional trust factor. This approach reduces friction while simultaneously making life more difficult for automated tools that only partially imitate a browser.
What Exactly an Anti-Bot System Looks For
From a practical point of view, anti-bot protection does not try to find one “perfect” sign of automation. It looks for a set of weak but consistent signals. This may be a combination of increased request frequency, a non-standard graphics profile, overly uniform behavior in a form, and instantaneous navigation across pages. Taken separately, each of these factors may have a harmless explanation. Together, they form a convincing picture.
That is exactly why modern solutions are built around risk scoring. Every action, attribute, or deviation either adds to or reduces trust. Based on the total score, the system decides whether to allow the request, restrict it, require additional verification, or block access completely.
This approach is also convenient because it allows protection to be adapted to a specific section of the website. One level of sensitivity may be acceptable for a public low-risk page, while another is required for a login form, a payment scenario, or access to valuable data.
Why Proxies Matter for Anti-Bot Protection
The network layer remains the first line of anti-bot verification, but its capabilities are often insufficient if automated traffic is distributed through proxy infrastructure. For a website, an IP address is only an external sign of the request source, not a reliable confirmation of who is actually performing the action. If the system sees requests coming from data center addresses, suspicious routing nodes, or known intermediary networks, the risk score rises. But when traffic passes through a more diverse network of addresses, the task becomes more difficult.
That is why modern anti-bot systems do not limit themselves to a simple IP blacklist. They take into account the type of address space, activity history, request density, geographic consistency, and the relationship between the IP and the other session parameters. Suspicion is caused not only by the address itself, but also by mismatches between the network source, the device, language settings, time zone, and behavioral model.
The use of proxies also explains why basic measures such as rate limiting do not always produce a sufficient result. If automated requests are distributed across many addresses, the load on each individual IP may appear moderate. Under such conditions, websites have to correlate network signals with browser fingerprints, behavioral patterns, and session consistency. Otherwise, automation can bypass crude network restrictions too easily simply by changing its network exit points.
This leads to the main conclusion: proxies do not eliminate network verification, but they reduce its standalone value. That is why, in real anti-bot systems, IP analysis is only one layer of protection, operating in conjunction with deeper technical and behavioral signals.
Stay Ahead of Anti-Bot Checks
Premium residential proxies for reliable web access.
Why Protection Must Be Adaptive
Any static scheme quickly becomes outdated. If a website relies on only one type of verification, automation gradually adapts specifically to it. That is why robust anti-bot systems do not fix rules once and for all, but constantly refine their signals and revise their thresholds.
Adaptability is especially important in two respects. First, the nature of traffic itself changes: new browser versions, new devices, new user scenarios. Second, the quality of automation changes: it becomes closer to real browser behavior and reproduces the external signs of an ordinary session more effectively. This means protection must not simply collect more data, but interpret it more precisely in context.
For this reason, the best results are usually delivered by systems that do not rely on a single mechanism, but combine network analysis, fingerprinting, behavioral analytics, and selective verification tasks into a unified decision-making model.
Conclusion
A website distinguishes a human from automation not by a single sign, but by a combination of technical and behavioral signals. First, network parameters and request frequency are assessed, then the browser environment is analyzed, after that behavior within the session is evaluated, and, if necessary, additional confirming mechanisms are activated.
The key principle of modern anti-bot protection is not total control, but a multilayered assessment of consistency. A real user usually leaves a natural, internally coherent trace: their device, rendering, movements, typing pace, and navigation logic form an understandable picture. Automation more often reveals itself not through one crude failure, but through a series of small discrepancies that become noticeable when taken together.
That is why effective protection is built not on a single check, but on a combination of methods. The more accurately a website correlates network, technical, and behavioral data, the more reliably it separates live interaction from automated traffic.